1. A thread can be at a safepoint or not be at a safepoint. When at a safepoint, the thread's representation of it's Java machine state is well described, and can be safely manipulated and observed by other threads in the JVM. When not at a safepoint, the thread's representation of the java machine state will NOT be manipulated by other threads in the JVM. [Note that other threads do not manipulate a thread's actual logical machine state, just it's representation of that state. A simple example of changing the representation of machine state is changing the virtual addresss that a java reference stack variable points to as a result of relocating that object. The logical state of the reference variable is not affected by this change, as the reference still refers to the same object, and two references variable referring to the same object will still be logically equal to each other even if they temporarily point to different virtual addresses].2. "Being at a safepoint" does not mean "being blocked" (e.g. JNI code runs at a safepoint), but "being blocked" always happens at a safepoint.3. The JVM may choose to reach a global safepoint (aka Stop-The-World), where all threads are at a safepoint and can't leave the safe point until the JVM decides to let it do so. This is useful for doing all sorts of work (like certain GC operations, deoptimization during class loading, etc.) that require ALL threads to be at a well described state.4. Some JVMs can bring individual threads to safepoint without requiring a global safepoint. E.g. Zing uses the term Checkpoint (first published in [1]) to describe a JVM mechanism that individually passes threads through thread-specidfic safepoints to perform certain very short operations on individual thread state without requiring a Stop-The-Wolrd pause.5. When you write Unsafe java code, you must assume that a safepoint MAY occur between any two bytecodes.6. Unsafe calls are not required to have safepoints within them (and many/most don't), but they MAY include one or more safepoints. E.g. an unsafe memoryCopy MAY include a periodic safepoint opportunities (e.g. take a safepoint every 16KB). Zing sure does, as we do a lot of under the hood work to keep TTSP in check.7. All [practical] JVMs apply some highly efficient mechanism for frequently crossing safepoint opportunities, where the thread does not actually enter a safepoint unless someone else indicates the need to do so. E.g. most call sites and loop backedges in generated code will include some sort of safepoint polling sequence that amounts to "do I need to go to a safepoint now?". Many HotSpot variants (OpenJDK and Oracle JDK) currently use a simple global "go to safepoint" indicator in the form of a page that is protected when a safepoint is needed, and unprotected otherwise. The safepoint polling for this mechanism amounts to a load from a fixed address in that page. If the load traps with a SEGV, the thread knows it needs to go to enter a safepoint. Zing uses a different, per-thread go-to-safepoint indicator of similar efficiency.8. All JNI code executes at a safepoint. No Java machine state of the executing thread can be changed or observed by it's JNI code while at a safepoint. Any manipulation or observation of Java state done by JNI code is achieved via JNI API calls that leave the safepoint for the duration of the API call, and then enter a safepoint again before returning to the calling JNI code. This "crossing of the JNI line" is where most of the JNI call and API overhead lies, but it's fairly quick (entering and leaving safepoint normally amounts to some CAS operations).
Wednesday, 4 September 2013
What is a Java Safepoint?
This is the best description of the behaviours of a safepoint in Java that I have come across, it was written by Gil Tene; CTO of Azul and posted to the mechanical sympathy mailing list run by Martin Thompson. I capture it here for my own reference.
Friday, 21 June 2013
How to install Siege for Mac OS X 10.8
Siege is a wonderful tool for benchmarking http urls. Unfortunately since Mountain Lion it can be a bit fidly to install, the main download website has a dmg file that once downloaded says that ones version of OSX is not supported; so build from source. And building from source has problems with X not being supplied by default.
Brew FTW.
So I resorted to bundled packagers, firstly fink but then Brew. Brew worked first time with little effort.
http://mxcl.github.io/homebrew/
ruby -e "$(curl -fsSL https://raw.github.com/mxcl/homebrew/go)"
brew doctor
brew install siege
siege.config
Then edit the .siegerc file generated by siege.config, setting connection from 'close' to 'keep-alive'. I also disable logging too.
Benchmarks can then be run as follows:
siege -c 100 -b http://www.google.com > /dev/null
Press ctrl-c when you want to stop the test and see the stats.
Sunday, 2 June 2013
Vagrant Script for compiling JDK 8 from source
I recently wanted to take a look at Java 8, without wanting to pollute my working environment. The JDK has a fair few dependencies that must be installed before it can be compiled. So I created the following Vagrantfile which I have chosen to share here.
Vagrant is a great wrapper for running virtual machines locally. After installing vagrant, to just type 'vagrant up' in the same directory as the following file and it will handle creating a 64bit Ubuntu VM locally, installing dependencies, checking out the head branch of JDK8 and compiling it.
After Vagrant has finished creating the VM, and compiling the JDK. You can log in to the Ubuntu instance by typing 'vagrant ssh' and from there you will be able to use the compiled JDK, make changes, recompile and so forth.
Vagrant is a great wrapper for running virtual machines locally. After installing vagrant, to just type 'vagrant up' in the same directory as the following file and it will handle creating a 64bit Ubuntu VM locally, installing dependencies, checking out the head branch of JDK8 and compiling it.
After Vagrant has finished creating the VM, and compiling the JDK. You can log in to the Ubuntu instance by typing 'vagrant ssh' and from there you will be able to use the compiled JDK, make changes, recompile and so forth.
# -*- mode: ruby -*-
# vi: set ft=ruby :
$checkoutAndCompileJDK = <<SCRIPT
sudo vagrant
cd ~
sudo apt-get update
sudo apt-get install -y mercurial
sudo apt-get install -y make
sudo apt-get install -y unzip
sudo apt-get install -y zip
sudo apt-get install -y openjdk-7-jdk
sudo apt-get install -y build-essential
sudo apt-get install -y libX11-dev libxext-dev libxrender-dev libxtst-dev
sudo apt-get install -y libcups2-dev
sudo apt-get install -y libfreetype6-dev
sudo apt-get install -y libasound2-dev
sudo apt-get install -y ccache
sudo apt-get install -y alsa
sudo apt-get install -y cups
sudo apt-get install -y xrender
sudo apt-get install -y libpng12-dev
sudo apt-get install -y libgif-dev
sudo apt-get install -y libfreetype6
sudo apt-get install -y pkg-config
hg clone http://hg.openjdk.java.net/jdk8/jdk8 jdk8
cd jdk8
bash ./get_source.sh
bash ./configure
make all
SCRIPT
Vagrant.configure("2") do |config|
config.vm.box = "precise64"
config.vm.box_url = "http://files.vagrantup.com/precise64.box"
config.vm.provision :shell, :inline => $checkoutAndCompileJDK
config.vm.provider :virtualbox do |vb|
vb.customize ["modifyvm", :id, "--memory", "4096"]
end
end
Friday, 17 May 2013
Modern CPU design: How fast is a single CPU core?
Up until 2003 CPUs clock rates were increasing rapidly, however since 2003 clock rates have maxed out at around 3GHz. This maxing out has happened because as electrical components have become smaller, unwanted effects occur such as current leakage. Eventually as the components get so small, the leakage can become so bad that more current goes in than useful work can occur. It over heats and becomes very unstable. There is some good news here though, the clock rate of CPUs may have plateaued for now but that does not mean that CPUs stopped getting faster.
GHz relates to CPU speed in much the same way as horse power relates to the speed of cars. That is, it does and it does not. There are ways to make a car go faster without increasing the horse power of the engine. And that is also true with CPUs.
So how do modern CPUs keep getting faster? A combination of being more efficient, and more parallel. By more parallel I do not just mean that more CPUs are appearing in modern computers; which is actually true in its own right but it is not the full story. I also mean that a single CPU is also becoming more parallel in itself than ever before.
As an example of this, try running the following Java code. This code iterates over an array of bytes, and assigns the value 42 to each element. Over and over again.
public class ByteArrayWrite {
public static void main( String[] args ) {
ByteArrayWrite b = new ByteArrayWrite();
System.gc();
b.run();
b.run();
b.run();
b.run();
b.run();
b.run();
b.tearDown();
}
private int arraySize;
private byte[] array;
public ByteArrayWrite() {
this.arraySize = 100000;
array = new byte[arraySize];
}
public void tearDown() {
for ( int j=0; j<arraySize; j++ ) {
if ( array[j] != 42 ) {
throw new IllegalStateException( "array writes were optimised out, invalidating the test" );
}
}
array = null;
}
protected void run() {
long startNanos = System.nanoTime();
int numItterations = 100000;
for ( int i=0; i<100000; i++ ) {
for ( int j=0; j<arraySize; j++ ) {
array[j] = 42;
}
}
long numOps = ((long) numItterations) * arraySize;
long durationNanos = System.nanoTime() - startNanos;
double durationMillis = durationNanos / 1000000.0;
double rateNS = ((double)numOps) / durationNanos;
System.out.println( String.format("%.2f array writes/ns [totalTestRun=%.3fms]", rateNS, durationMillis) );
}
}
At 3GHz a single CPU can perform approximately 3 operations per nanosecond (assuming one instruction per clock cycle). Running the code above on my 2.7GHz laptop printed out on average 35 array writes per nanosecond. That is a lot more than the 3 CPU instructions per ns that one would have expected given the clock rate. How is this possible?
The following diagram describes a single core from the latest Intel Haswell CPU.
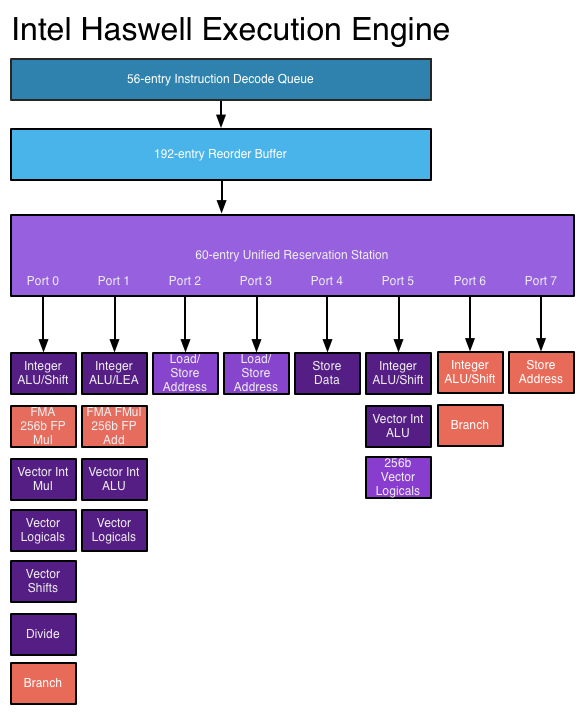
This diagram is interesting because it shows that a single Haswell CPU has 7 ports. Each port is capable of parallel execution of CPU instructions. Each of the ports has one or more execution units underneath it; 20 in total. On top of this, the instruction decoding and scheduling to ports happens in parallel with multiple decoders. Thus if given the opportunity a single 3GHz CPU can perform tens of instructions per clock cycle or more. Which explains why the Java code above beat the expected 3 ops per ns expectation. Now not all execution units are created equal, they are specialised to different tasks which is part of the reason why there is a scheduler assigning work to each of the ports. However the point stands. As programmers we think of code running on a single CPU as a linear sequence of steps, each one happening after the other.
Modern CPUs like the x86 offer the potential for incredible amounts of parallelism. With each new release of a CPU, we are seeing more CPU ports. Wider vector instructions. More execution units. More decoders. Wider data paths. In short, more and more parallelism within a single CPU. This parallelism is typically handled for us by the awesome work carried out by the hardware engineers. Thus our single threaded applications get executed faster without any extra work on our part. This makes coding for them very simple, while still getting many of the benefits parallelism.
Friday, 10 May 2013
Notes on Java 8's removal of PermSpace
The details were posted to the openjdk mailing list below. The short version is that PermSpace is being renamed ;)
http://mail.openjdk.java.net/pipermail/hotspot-dev/2012-September/006679.html
- Java 7: Interned strings moved to Heap
- Java8: Moves Permspace from heap to a native memory region called 'Metaspace' and changes it to automatically grow in size by default
Sunday, 14 April 2013
How can JVM jitter get caused by a for loop with no object allocations?
It is not uncommon for Java programs to pause for periods of time, sometimes long periods. Garbage Collection is usually the culprit and there is a lot of documentation on its effects. However it is not the only cause, and while benchmarking I/O performance on Java I hit an unusual case where summing up the contents of an array of bytes caused every other Java thread to block for 2.5 seconds while not blocking or slowing down itself. Very curious, and it highlights that the side effects between Java threads can be very subtle and non-obvious. For this blog post I have documented how I performed the test, and how I tracked down the offender. Along the way I cover some aspects of how Hotspot works its magic, including compilation of Java code and when it will halt the execution of all Java threads.
Alexey Ragozin reports that the Oracle Hotspot implementation will perform a request to stop all threads when:
For methods that take a very long time to complete, or perhaps never complete because they stay within a loop then the JVM is capable of optimising the method from a safe point in the loop. It can then swap in the new implementation when the method is at that same point. HotSpot calls this 'On Stack Replacement' or OSR for short. Now my assumption has always been that this hot replacement would only slow down the thread that was executing the code, and in most cases not even that thread should ever suffer.
Hotspot's compilation can be monitored by adding the following JVM flag: '-XX:+PrintCompilation'
This flag resulted in the following output:
To see when Java is halting the world, add the following flag to the command line: '-XX:+PrintGCApplicationStoppedTime'. Despite its misleading name, this option prints out the time that the JVM sits waiting for all threads to stop. It is not just about GC time.
For me, this flag resulted in the following smoking gun.
It turns out that during start up of the JVM, Oracle keep biased locking disabled for the first four seconds. This is because there is a lot of contention within the JVM during this startup window and thus they delay turning it on and turning it on is a Stop the World event. The stop the world event then had to wait for a safe point to be reached, and it so happens that the thread running had no safe point within its for loop which took a little while to run to completion.
The Problem
Here is the offending code, it consists of two loops that together sum up the contents of an array of bytes 'n' times. No obvious causes for blocking other JVM threads here. It does not synchronise, or use volatile, CAS, wait, or notify. In fact the data structures are all created on one thread and accessed from that one thread without sharing it.
public long invoke( int targetCount ) {
long sum = 0;
for ( int i=0; i<targetCount; i++ ) {
for ( int j=0; j<arraySize; j++ ) {
sum += array[j];
}
}
return sum;
}
This code runs on my laptop in 2.4 seconds, averaging 2.5 array reads and summations every nanosecond. This benchmark did not become interesting until I decided to also measure the JVM jitter. My end goal was to benchmark disk IO, and JVM jitter is a way to see the side effects of overloading the IO system and kernel (say by memory mapping too much data); however it showed something very interesting in the totally in-memory case that I had not expected. The jitter thread got blocked for 2.5s, it was a one off block that did not repeat in the same run; but it did occur at the same point of every run. Why would a for loop cause other threads to block? EVER?Measuring JVM Jitter
Perhaps the problem was with how I measured the jitter. To measure I started a background daemon thread that repeatedly sleeps for 1ms and then measures how long after the 1ms period it took for it to actually wake up. It then stores the max length of blocked time and repeats. Java is well known for having limitations in its reading of time, and most thread schedulers are optimised for speed over accuracy thus it is expected that the thread will pretty much always wake up some time after the 1ms period. The question is, how long after. I hope that you agree that this code works well and does what it says on the tin.public class MeasureJitter extends Thread {
private AtomicLong maxJitterWitnessedNS = new AtomicLong(0);
public MeasureJitter() {
setDaemon( true );
}
public void reset() {
maxJitterWitnessedNS.set( 0 );
}
public double getMaxJitterMillis() {
return maxJitterWitnessedNS.get()/1000000.0;
}
public void printMaxJitterMillis() {
System.out.println( "getMaxJitterMillis() = " + getMaxJitterMillis() );
}
@Override
public void run() {
super.run();
long preSleepNS = System.nanoTime();
while( true ) {
try {
Thread.sleep( 1 );
} catch (InterruptedException e) {
e.printStackTrace();
}
long wakeupNS = System.nanoTime();
long jitterNS = Math.max(0, wakeupNS - (preSleepNS+1000000));
long max = Math.max( maxJitterWitnessedNS.get(), jitterNS );
maxJitterWitnessedNS.lazySet( max );
preSleepNS = wakeupNS;
}
}
}
It turns out that on my system the normal latency was 0.4ms, however it always jumped to 2.5s at the same point of the test run. Every time. That is a jump from 0.4ms to 2500ms, a huge jump. When benchmarking Java, one always skips the first values as they are quite erratic and slow. However this peaked my interest because while the background jitter measuring thread was delayed by 2.5 seconds the throughput of the array counting was not slowed at all. So the question was, why? And inorder to understand it, I had to peel back the layers of the JVM.Java and Stop the World events
There are times when Java has to halt all threads. The most famous of these is Garbage Collection. A recorded statistic for Java is an average of 1 second of halting all Java threads per 1-2Gb of heap space; this statistic is obviously highly variable. In this case, the heap space was 500Mb, there were no objects being allocated and the main work thread was not stopped. It was the background daemon thread that was getting the Jitter. So this did not sound like GC, but just to be sure I added -XX:+PrintGCDetails to the JVM start up command and confirmed that there was indeed no GC going on. My next suspicion was that it was the Daemon thread that was not getting scheduled for some reason. However the Unix thread schedulers are very efficient, and while it may assign the jitter thread to the same cpu core that was doing the work that would not block it from being run for two and a half seconds. I would have expected either 1) another core to have stolen the work before 2.5 seconds was up or 2) for the busy core to have been paused and the other thread run (this is called preemption). In either case the result should have been variable. With variations in the jitter time, and in the case of stealing time from the worker thread, slowing the worker thread down. None of this was the case, so my suspicion fail upon Hotspot itself. Was Hotspot blocking other threads as a side effect of generating native assembler code?Alexey Ragozin reports that the Oracle Hotspot implementation will perform a request to stop all threads when:
- Garbage collection pauses (depends on the GC algorithm being used)
- Code deoptimization (in response to new information from newly loaded classes, null pointer exceptions, division by zero traps and so forth)
- Flushing code cache
- Class redefinition (e.g. hot swap or instrumentation)
- Biased lock revocation (and as we learned in this post, turning the BiasedLock mechanism on)
- Various debug operation (e.g. deadlock check or stacktrace dump)
Hotspot Compilation on modern JVMs
The latest Oracle VMs use tiered compilation. That is they start executing Java Byte Codes via an interpretor. Which is a flash back in time to Java's origins, back before the days of JIT and Hotspot; to a time when Java had a deserved reputation for being very slow. Very very slow ;) The VM still executes code via the interpretor so that it can startup faster, and to gather some statistics to inform what it should compile/optimise and how. Every method call has with it a counter, as does the back edge of every for loop that has not been unrolled (including nested for loops). When the sum of these two counters exceeds a threshold, then Hotspot will schedule a request to compile the method. By default this compilation happens in the background, and it then replaces the interpreted version of the method when it is next called.For methods that take a very long time to complete, or perhaps never complete because they stay within a loop then the JVM is capable of optimising the method from a safe point in the loop. It can then swap in the new implementation when the method is at that same point. HotSpot calls this 'On Stack Replacement' or OSR for short. Now my assumption has always been that this hot replacement would only slow down the thread that was executing the code, and in most cases not even that thread should ever suffer.
Hotspot's compilation can be monitored by adding the following JVM flag: '-XX:+PrintCompilation'
This flag resulted in the following output:
2632 2% com.mosaic.benchmark.datastructures.array.UncontendedByteArrayReadBM::invoke @ 14 (65 bytes) 6709 2% made not entrant com.mosaic.benchmark.datastructures.array.UncontendedByteArrayReadBM::invoke @ -2 (65 bytes)The format for this output is documented here. In short it says that the method that held the for loops above was compiled to native code, swapped in to the running method via OSR and then 4.1 seconds later the optimised version of the code was flagged sub optimal and to be replaced (made not entrant). Was this the cause? According to the documentation of this output, marking the method none entrant does not prevent the method that is currently running. At some point the JVM should swap the method over to a newly compiled version and mark the old version as a zombie, ready to be cleaned out. Marking it non-entrant is designed to stop any new methods from running that version of the code. Could this be blocking other threads? I'd hope not as events that invalidate optimised code is fairly common in Java. Java is cited as having cases where it can run faster than statically compiled C code. This happens because Java can look at how it is really being used at run time and re-optimise the code on the fly. Causing big latencies here would kill that selling point of Java. So the question is, how do we get a smoking gun that proves that this is the problem?
Debugging Hotspot Safe Points
The JVM cannot just stop all threads. When the JVM wants to perform an exclusive change it has to register its desire to stop all threads and then it has to wait for the threads to stop. Threads only check the need to pause at 'safe points', which have been nicely documented by Alexey Ragozin in his blog post titled Safepoints in HotSpot JVM. The safepoints are on JNI boundaries (enter or exit), or calling a Java method.To see when Java is halting the world, add the following flag to the command line: '-XX:+PrintGCApplicationStoppedTime'. Despite its misleading name, this option prints out the time that the JVM sits waiting for all threads to stop. It is not just about GC time.
For me, this flag resulted in the following smoking gun.
Total time for which application threads were stopped: 2.5880809 secondsThe pause event was identical to the jitter being reported. To understand this further the following two JVM flags have to be used: ' -XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1'.
vmop [threads: total initially_running wait_to_block] [time: spin block sync cleanup vmop] page_trap_count 4.144: EnableBiasedLocking [ 10 1 1 ] [ 2678 0 2678 0 0 ] 0 Total time for which application threads were stopped: 2.6788891 secondsThis output tells us that the JVM waited 2.678 seconds to stop the world and that the reason for wanting to stop the world was to enable biased locking. Biased locking, as it turns out is an optimisation for lock acquisitions which are usually only locked by the same thread (but could be locked by other threads). It reduces the cost of the same thread re-acquiring the same lock at the expense of increasing the cost for any other thread that wants to acquire it. This then is our smoking gun.
It turns out that during start up of the JVM, Oracle keep biased locking disabled for the first four seconds. This is because there is a lot of contention within the JVM during this startup window and thus they delay turning it on and turning it on is a Stop the World event. The stop the world event then had to wait for a safe point to be reached, and it so happens that the thread running had no safe point within its for loop which took a little while to run to completion.
Conclusions
JVM jitter occurs anytime that the JVM wants to stop all threads so that it can gain exclusive access to its internal data structures. How long this jitter lasts depends on how long it takes to stop all of the threads, and this in turn depends on when the threads will reach the next safe point. Calling native methods that take a long time to finish, or using long loops that do not call out to any other method can result in very long delays. We saw a 2.5s delay here due to a for loop iterating over an array of bytes. Admit-ably this is a contrived micro benchmark, however Gil Tene CTO from Azul Systems has reported seeing delays like this of 10s or more in production systems. The 10s example that he gave was from a Clojure program that involved a large memory copy.Sunday, 24 February 2013
Are Java Assertions Enabled?
A quick tip if you ever need to test whether assertions are enabled in Java, without having to throw and catch an assertion exception.
boolean ASSERTIONS_ENABLED = false;
assert ASSERTIONS_ENABLED = true;
This code sets ASSERTIONS_ENABLED to false and then, if and only if assertions are enabled then the assert expression will run. The assert expression sets ASSERTIONS_ENABLED to true and returns true. Thus no exception will be thrown.
Thursday, 7 February 2013
Java 8 Early Access on OSX
Hurrah to Oracle and Apple. I had all but given up seeing the latest
production releases of Java appearing on OSX anytime soon. Today I
have been playing with the early access release of Java 8 on my mac. Fantastic
work, thank you!
Monday, 28 January 2013
Unit Testing: Mandatory or Optional?
I recently came across this nice post (http://agilewarrior.wordpress.com/2012/10/06/its-not-about-the-unit-tests/) and I wanted to share it with you, as it carries a very important message that separates the capable Software Engineers from the great Software Engineers.
In our industry, when we come across a practice that helps us to improve we tend to shout about it and over state its impact. In this post the author points out that Unit Testing is not commonly used in iPhone and iPad development; and yet their software is often highly regarded anyway. As an individual who was taught that high quality software had to be unit tested, this was earth shattering news for him; it literally led to many sleepless nights while he wrestled to incorporate this observation into his view of the world. Needless to say, unit testing is a very powerful tool and that it does belong in every professional software engineers tool box. But knowing when to use it, when not to use it and how to get the best gains from it is important. In fact, like any tool, misusing it can be just as bad as not using it at all. And most of all, unit testing is not a substitute for caring about the product that we are crafting.
Subscribe to:
Posts (Atom)