Up until 2003 CPUs clock rates were increasing rapidly, however since 2003 clock rates have maxed out at around 3GHz. This maxing out has happened because as electrical components have become smaller, unwanted effects occur such as current leakage. Eventually as the components get so small, the leakage can become so bad that more current goes in than useful work can occur. It over heats and becomes very unstable. There is some good news here though, the clock rate of CPUs may have plateaued for now but that does not mean that CPUs stopped getting faster.
GHz relates to CPU speed in much the same way as horse power relates to the speed of cars. That is, it does and it does not. There are ways to make a car go faster without increasing the horse power of the engine. And that is also true with CPUs.
So how do modern CPUs keep getting faster? A combination of being more efficient, and more parallel. By more parallel I do not just mean that more CPUs are appearing in modern computers; which is actually true in its own right but it is not the full story. I also mean that a single CPU is also becoming more parallel in itself than ever before.
As an example of this, try running the following Java code. This code iterates over an array of bytes, and assigns the value 42 to each element. Over and over again.
public class ByteArrayWrite {
public static void main( String[] args ) {
ByteArrayWrite b = new ByteArrayWrite();
System.gc();
b.run();
b.run();
b.run();
b.run();
b.run();
b.run();
b.tearDown();
}
private int arraySize;
private byte[] array;
public ByteArrayWrite() {
this.arraySize = 100000;
array = new byte[arraySize];
}
public void tearDown() {
for ( int j=0; j<arraySize; j++ ) {
if ( array[j] != 42 ) {
throw new IllegalStateException( "array writes were optimised out, invalidating the test" );
}
}
array = null;
}
protected void run() {
long startNanos = System.nanoTime();
int numItterations = 100000;
for ( int i=0; i<100000; i++ ) {
for ( int j=0; j<arraySize; j++ ) {
array[j] = 42;
}
}
long numOps = ((long) numItterations) * arraySize;
long durationNanos = System.nanoTime() - startNanos;
double durationMillis = durationNanos / 1000000.0;
double rateNS = ((double)numOps) / durationNanos;
System.out.println( String.format("%.2f array writes/ns [totalTestRun=%.3fms]", rateNS, durationMillis) );
}
}
At 3GHz a single CPU can perform approximately 3 operations per nanosecond (assuming one instruction per clock cycle). Running the code above on my 2.7GHz laptop printed out on average 35 array writes per nanosecond. That is a lot more than the 3 CPU instructions per ns that one would have expected given the clock rate. How is this possible?
The following diagram describes a single core from the latest Intel Haswell CPU.
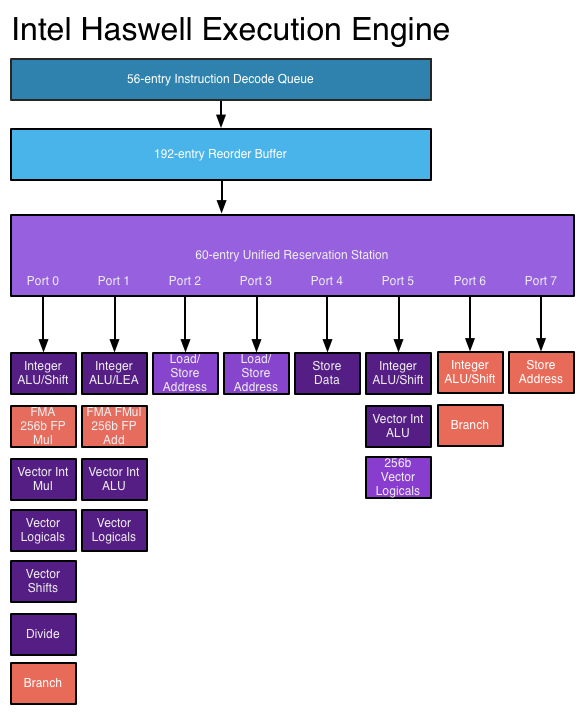
This diagram is interesting because it shows that a single Haswell CPU has 7 ports. Each port is capable of parallel execution of CPU instructions. Each of the ports has one or more execution units underneath it; 20 in total. On top of this, the instruction decoding and scheduling to ports happens in parallel with multiple decoders. Thus if given the opportunity a single 3GHz CPU can perform tens of instructions per clock cycle or more. Which explains why the Java code above beat the expected 3 ops per ns expectation. Now not all execution units are created equal, they are specialised to different tasks which is part of the reason why there is a scheduler assigning work to each of the ports. However the point stands. As programmers we think of code running on a single CPU as a linear sequence of steps, each one happening after the other.
Modern CPUs like the x86 offer the potential for incredible amounts of parallelism. With each new release of a CPU, we are seeing more CPU ports. Wider vector instructions. More execution units. More decoders. Wider data paths. In short, more and more parallelism within a single CPU. This parallelism is typically handled for us by the awesome work carried out by the hardware engineers. Thus our single threaded applications get executed faster without any extra work on our part. This makes coding for them very simple, while still getting many of the benefits parallelism.
No comments:
Post a Comment